 I am an associate prof at IT University of Copenhagen. I mainly work on algorithms for the analysis of complex networks, and on applying the extracted knowledge to a variety of problems.
My background is in Digital Humanities, i.e. the connection between the unstructured knowledge and the coldness of computer science.
I have a PhD in Computer Science, obtained in June 2012 at the University of Pisa. In the past, I visited Barabasi's CCNR at Northeastern University, and worked for 6 years at CID, Harvard University.
I am an associate prof at IT University of Copenhagen. I mainly work on algorithms for the analysis of complex networks, and on applying the extracted knowledge to a variety of problems.
My background is in Digital Humanities, i.e. the connection between the unstructured knowledge and the coldness of computer science.
I have a PhD in Computer Science, obtained in June 2012 at the University of Pisa. In the past, I visited Barabasi's CCNR at Northeastern University, and worked for 6 years at CID, Harvard University. News on Social Media: It’s not Real if I don’t Like it
The spread of misinformation — or “fake news” — is an existential threat for online social media like Facebook and Twitter. Since fake news has the power to influence elections, it has attracted legislative attention. And online social media don’t like legislative attention: Zuck wants to continue doing whatever he is doing. Thus, they need to somehow police content on their platforms before somebody else polices it for them. Unfortunately, the way they chose to do so actually backfires, as I show in “Distortions of Political Bias in Crowdsourced Misinformation Flagging“, a paper I just published with Luca Rossi in the Journal of the Royal Society Interface.
The way fact checking (doesn’t) work on online social media at the moment could be summarized as “semi-supervised crowdsourced flagging”. When a news item is shared on the platform, the system allows the readers to flag it for removal. The idea is that the users know when an item is a case of fake reporting, and will flag it when it is. Flags are then fed to a machine learning algorithm. The task of this algorithm is to filter out noise. Since there are millions of users on Facebook, practically every URL shared on the platform will be flagged at least once. After the algorithm pass, a minority of flagged content will be handed to experts, who will fact-check it*.

Sounds great, right? What could possibly go wrong? That’s what I defiantly asked Luca when he prodded me to look at the data of what was being passed to the expert fact checkers. As Buzzfeed would say, the next thing I saw shocked me. He showed me the top ten websites receiving the highest number of expert fact-checks in Italy — meaning that they received so many flags that they passed the algorithmic test. All major national Italian newspapers were there: Repubblica, Corriere, Sole 24 Ore. These ain’t your Infowars or your Breitbarts. They have clear leanings, but they are not extremist and they usually report genuinely, albeit selectively and with a spin. The fact-checkers did their job and duly found them not guilty.
So what gives? Why are most flags attached to mostly mild leaning, genuine reporting? Luca and I developed a model trying to explain this phenomenon. Our starting point was re-examining how the current system works: users see news, flag the ones that don’t pass the smell test, and those get checked. It’s the smell test that doesn’t pass the smell test. There are a few things impairing our noses: confirmation bias and social homophily.

Image from https://fs.blog/2017/05/confirmation-bias/
Confirmation bias means that a user will give an easier pass to a piece of news if the user and the news share the same ideological bias. Strongly red users will be more lenient with red fake news but might flag a more truthful blue news item, and vice versa. Social homophily means that people tend to be friends with people with a similar ideological leaning. Red people have red friends, blue people have blue friends. It’s homophily that gives birth to filter bubbles and echo chambers.
So how do these two things cause flags to go to popular neutral sources? The idea is that extremism is rare — otherwise it wouldn’t be extreme. Thus, most news organizations and users are neutral. Moreover, neutral news items will reach every part of the social network. They are produced by the most popular organizations and, on average, any neutral user reading them has a certain likelihood to reshare them to their friends, which may include more extreme users. On the other hand, extreme content is rare and is limited to its echo chambers.

Image from “MIS2: Misinformation and Misbehavior Mining on the Web”
This means that neutral content can reach the red and blue bubbles, but that extreme red and blue content will not get out of those same bubbles. An extreme red/blue factional person will flag the neutral content: it is too far from their worldview. But they will never flag the content of opposite color, because they will never see it. The fraction of neutral users seeing and flagging the extreme content is far too low to compensate.
Luca and I built two models. The first has the right ingredients: it takes into account homophily and confirmation bias and it is able to exactly reproduce the flagging patterns we see in real world data. The model confirms that it is the most neutral and most truthful news items that get flagged the most (see image below, to the left). The second model, instead, ignores these elements, just like the current flagging systems. This second model tells us that, if we lived in a perfect world where people objectively evaluate truthfulness without considering their own biased worldview, then only the most fake content would be flagged (see image below, to the right). Sadly, we don’t live in such a world, as the model cannot reproduce the patterns we observe. Sorry, the kumbaya choir practice is to be rescheduled to an unspecified date (also, with COVID still around, it wasn’t a great idea to begin with).
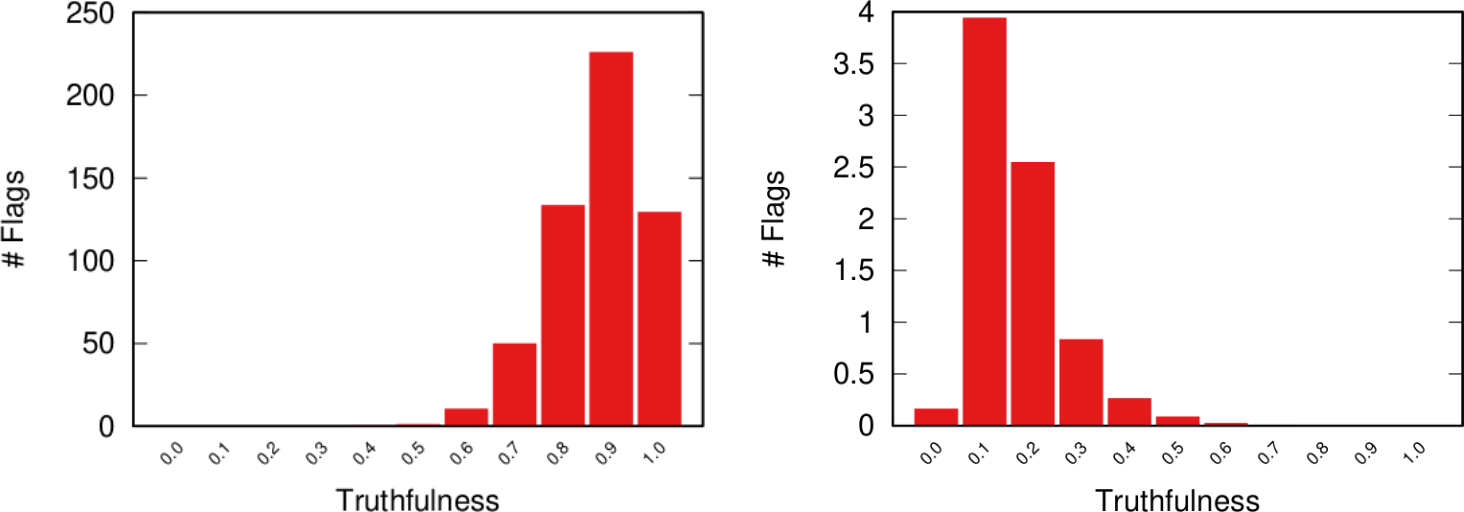
From our paper: the number of flags (y axis) per value of news “truthfulness” (x axis) in the model accounting for factionalism (left) and not accounting for factionalism (right). Most flags go to highly truthful news when accounting for factionalism.
Where to go from here is open to different interpretations. One option is to try and engineer a better flagging mechanism that can take this factionalism into account. Another option would be to give up altogether: if it’s true that the real extreme fake content doesn’t get out of the echo chamber, why bother policing it? The people consuming it wouldn’t believe you anyway. Luca and I will continue exploring the consequences of the current flagging mechanisms. Our model isn’t perfect and requires further tuning. So stay tuned for more research!
* Note that users can flag items for multiple reasons (violence, pornography, etc). This sort of outsourcing is done only for fact-checking, as far as I know.













 To illustrate my point consider two API systems. The first system, A1, gives you 100 connections per request, but imposes you to wait two seconds between requests. The second system, A2, gives you only 10 connections per request, but allows you a request per second. A2 is a better system to get all users with fewer than 10 connections — because you are done with only one request and you get one user per second –, and A1 is a better system in all other cases — because you make far fewer requests, for instance only one for a node with 50 connections, while in A2 you’d need five requests.
To illustrate my point consider two API systems. The first system, A1, gives you 100 connections per request, but imposes you to wait two seconds between requests. The second system, A2, gives you only 10 connections per request, but allows you a request per second. A2 is a better system to get all users with fewer than 10 connections — because you are done with only one request and you get one user per second –, and A1 is a better system in all other cases — because you make far fewer requests, for instance only one for a node with 50 connections, while in A2 you’d need five requests.




{kind=link}
{kind=link}
{kind=link}
{kind=link}