Birds of a Feather Scam Together
In Italy we have a saying:
He who walks with the lame learns how to limp
It means that the company you keep will influence your behavior, more often than not in a negative way — never mind the fact that Judas had impeccable friends. Setting my mind on how to verify this tidbit of ancient wisdom, I decided to investigate how the fraudulent behavior of some businesses might correlate with that of the other companies they work with. Does doing business with a crook say something about you? Will Mexican drug cartels ever recoup the damage to their reputation when it turns out they do business with European banks?
The result is the paper “Birds of a feather scam together: Trustworthiness homophily in a business network” published last month in the Social Networks journal. I wrote this paper with Mauro Barone at the Agenzia delle Entrate, the Italian equivalent of the IRS in the US. The idea is simple. We want to answer the question: is the level of fraud committed by a business correlated with the level of fraud committed by its customer/supplier businesses?

I bet none of these birdbrains filled in their 1040 this year.
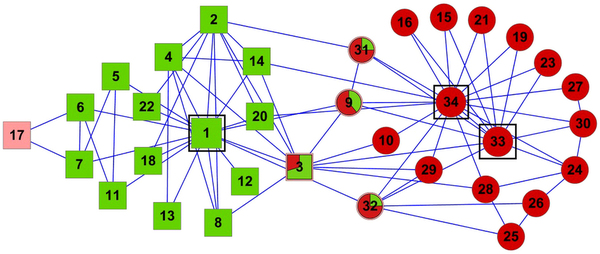
To answer the question we analyze a business-to-business (B2B) network. Each node in the network is a company, and it connects to other companies with directed edges. The edge goes from a provider to a customer, it follows the flow of goods and services. These connections are weighted according to the monetary value of the total transaction value during the year. The network contains all the relationships of a few thousands audited Italian businesses, centered on one Italian region: Tuscany.
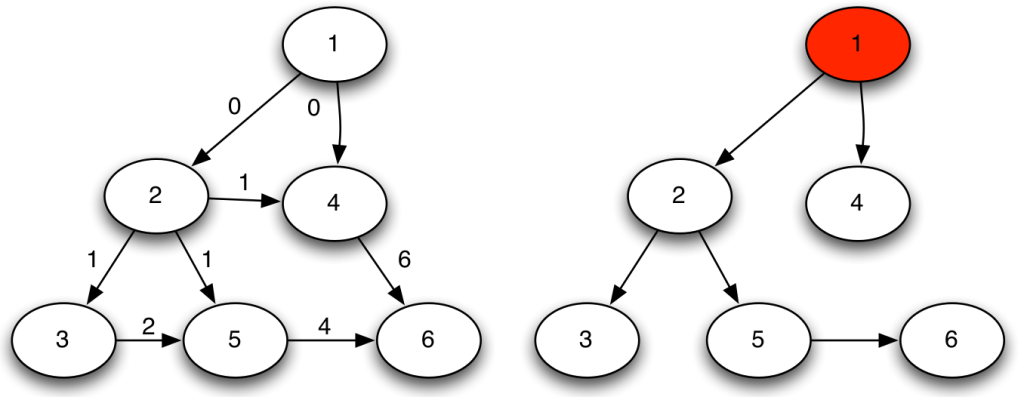
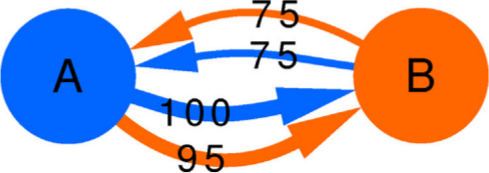
The peculiarity of the data structure that allow us to speak about tax fraud is that each connection is registered twice. Say we have business A and business B. The “A sold to B” connection should be reported by both A and B: A says how much it sold, and B says how much it purchased. See the example below: the blue edges are A’s declarations, and the orange edges are B’s. The two businesses agree on how much B sold to A (75 Euros), but they disagree on how much A sold to B.
Finding who’s trustworthy and who’s not seems, at first sight, an easy problem. If a business constantly misreports its transactions with its customer/supplier network, then we have good ground to suspect something fishy is going on. However, it’s not that easy. Say we decide a mismatch of 5 Euros is divided into 2.5 blamed on A and 2.5 blamed on B. We might think we’re doing a neutral operation, but we aren’t. What appears to be fair — shifting the blame equally to both actors involved in a disagreement — is already a heavy judgment. Maybe the fault lays completely on B, and A is a blameless victim. We all know how the story ends if we simply wash our hands of the problem like Pontius Pilate: with brigands freed and prophets on the cross.
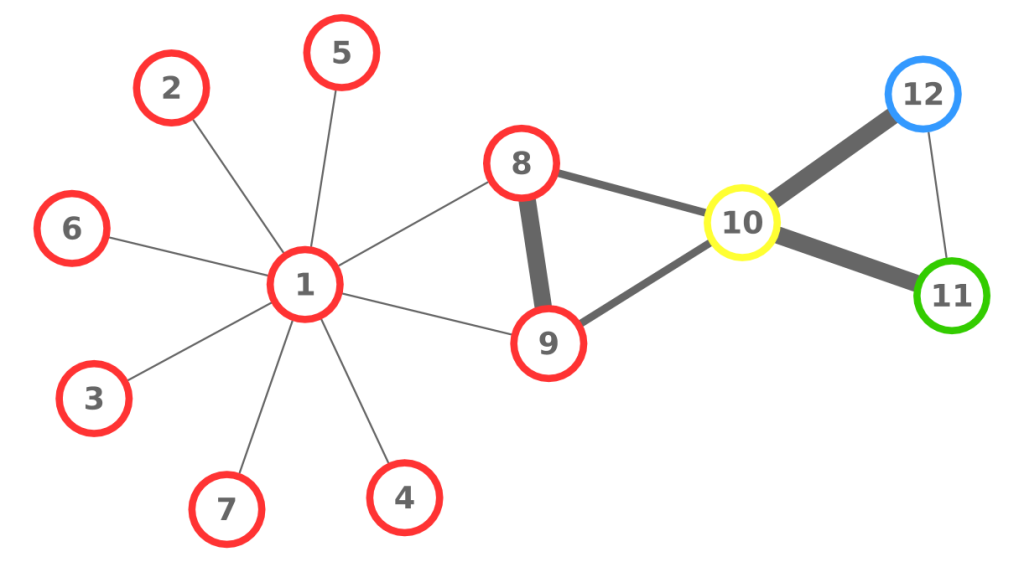
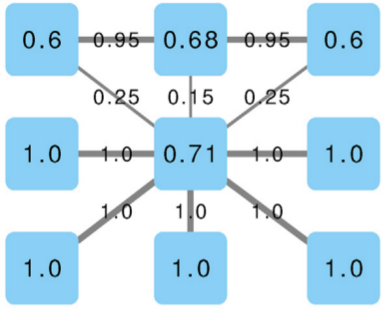
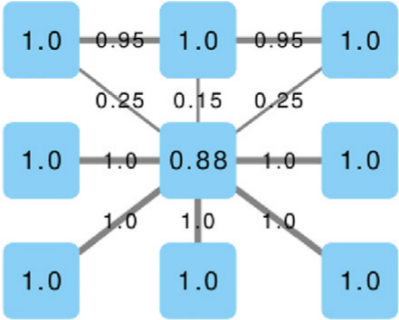
Paradoxically, if you simply average mismatches, the larger you are, the more you can con. The vast majority of businesses are honest thus, if you have a lot of relationships, they will mostly check out and bring your average match value up. At that point, you can tactically limit your misreports to a few connections and thus evade your taxes. The network also has a broad degree distribution, meaning that most businesses have few connections. This means that your victims will not have enough honest links to make up for the curveball you just threw at them. You can see an example below: the number on the node is their average edge weight, which is the match level of the connection — the total amount of Euros accounted for over the total transaction value (in the A-B example above, we have 75+75+100+95=345 total edge value, but only 340 accounted for given the mismatch of 5, thus the edge weight would be 340/345= 0.9855). Even though the hub has the most fraudulent connections — edges with low match values — its average is higher than that of its victims.
We solve this problem by taking these average mismatches only as a starting condition. At each iteration, we recalculate the average by re-weighting connections according to the trustworthiness equilibrium. The trick is to do it in an asymmetric way. If the previous iteration’s trustworthiness of A was larger than B’s, then in this iteration the mismatch for A is reduced, thus more of the blame will end on B. In practice, if on average we trusted A more, then we’re going to keep doing so in its other cases of mismatch. We don’t let a speck in A’s eye to make us miss the plank in B’s. (Man, my Biblical references today are on point!)
The exact mathematical formulation of this trick is in the paper. In practice, in our example above, the honest businesses below the hub siphon out all its trustworthiness — as they should. They leave it dealing with the businesses at the top, which are corroborating each other honesty with their own high-match links. After a few iterations, the hub ends up being the only business we should not trust — see below (note that I changed the node’s trust value, but I kept the edges constant, as showing the asymmetric correction would make the picture more confusing). In the paper we show that now we break the relationship between the trustworthiness score and the topological characteristics of the nodes: they are now being judged not by their position, but by their actions.
So: is it true that the friends of lame businesses are picking up limps? Yes it is: the difference in trustworthiness levels is a significant indicator whether a connection between two businesses is there or not. In practice, you can use it to predict future links in the B2B network. A strong match on trustworthiness doubles the chances that two businesses are connected to each other when compared to businesses with very different trustworthiness levels.
Making a point about Italian popular wisdom is all good and well, but this paper has a few more things to say. The trustworthiness score as we defined it has some interesting practical applications when it comes to predict which businesses to audit. If a low-trust business is audited, its probability of being fined — meaning something was indeed fishy — is ten percentage points higher than a high-trust business. Since our sample comes from audited businesses, it is not randomly selected: we’re observing businesses that were already suspect. So, if anything, this is an underestimation of the power of our measure: if we’re able to weed out the small crooks from the big ones, we’re probably going to do an even better job distinguishing innocents and culprits.

I think that this paper can do good for honest businesses. To be audited is a long and painful process: if you can skip it because the Agenzia delle Entrate knows how to find the bad guys, you can save time, energy, and peace of mind. And the crooks? Well, the crooks will have to render unto Caesar the things which are Caesar’s.