Entropy Applied to Shopping
I don’t know about you guys, but when it comes to groceries I show behaviors that are strongly reminiscent of Rain Man. I go to the supermarket the same day of the week (Saturday) at the same time (9 AM), I want to go through the shelves in the very same order (the good ol’ veggie-cookies-pasta-meat-cat food track), I buy mostly the same things every week. Some supermarkets periodically re-order their shelves, for reasons that are unknown to me. That’s enraging, because it breaks my pattern. The mahātmā said it best:

Amen to that. As a consequence, I signed up immediately when my friends Riccardo Guidotti and Diego Pennacchioli told me about a paper they were writing about studying the regularity of customer behavior. Our question was: what is the relationship between the regularity of a customer’s behavior and her profitability for a shop? The results are published in the paper “Behavioral Entropy and Profitability in Retail“, which will be presented in the International Conference on Data Science and Advanced Analytics, in October. To my extreme satisfaction the answer is that the more regular customers are also the most profitable. I hope that this cry for predictability will reach at least the ears of the supermarket managers where I shop. Ok, so: how did we get to this conclusion?
First, we need to measure regularity in a reasonable way. We propose two ways. First, a customer is regular if she buys mostly the same stuff every time she shops, or at least her baskets can be described with few typical “basket templates”. Second, a customer is regular if she shows up always at the same supermarket, at the same time, on the same day of the week. We didn’t have to reinvent the wheel to figure out a way for evaluating regularity in signals: giants of the past solved this problem for us. We decided to use the tools of information theory, in particular the concept of information entropy. Information entropy tells how much information there is in an event. In general, the more uncertain or random the event is, the more information it will contain.
If a person always buys the same thing, no matter how many times she shops, we can fully describe her purchases with a single bit of information: the thing she buys. Thus, there is little information in her observed shopping events, and she has low entropy. This we call Basket Revealed Entropy. Low basket entropy, high regularity. Same reasoning if she always goes to the same shop, and we call this measure Spatio-Temporal Revealed Entropy. Now the question is: what does happen to a customer’s expenditure for different levels of basket and spatio-temporal entropy?
To wrap our heads around these two concepts we started by classifying customers according to their basket and spatio-temporal entropy. We used the k-Means algorithm, which simply tries to find “clumps” in the data. You can think of customers as ants choosing to sit in a point in space. The coordinates of this point are the basket and spatio-temporal entropy. k-Means will find the parts of this space where there are many ants nearby each other. In our case, it found five groups:
- The average people, with medium basket and spatio-temporal entropy;
- The crazy people, with unpredictable behavior (high basket and spatio-temporal entropy);
- The movers, with medium basket entropy, but high spatio-temporal entropy (they shop in unpredictable shops at unpredictable times);
- The nomads, similar to the movers, with low basket entropy but high spatio-temporal entropy;
- The regulars, with low basket and spatio-temporal entropy.
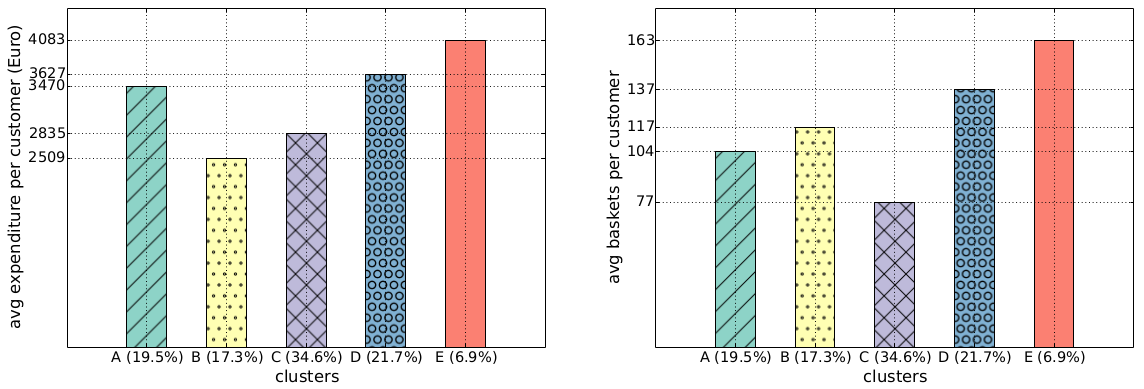
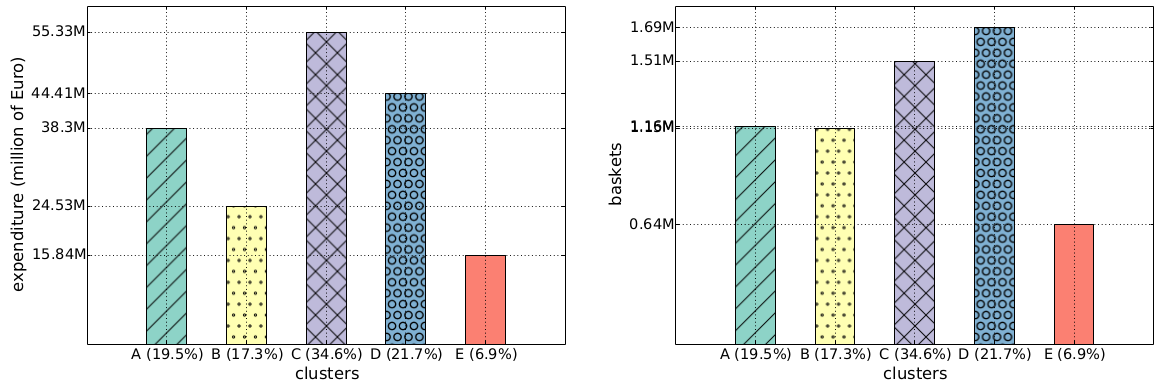
Once you cubbyholed your customers, you can start doing some simple statistics. For instance: we found out that the class E regulars spend more per capita over the year (4,083 Euros) than the class B crazy ones (2,509 Euros, see the histogram above). The regulars also visit the shop more often: 163 times a year. This is nice, but one wonders: why haven’t the supermarket managers figured it out yet? Well, they may have been, but there is also a catch: incurable creatures of habit like me aren’t a common breed. In fact, if we redo the same histograms looking at the group total yearly values of expenditures and baskets, we see that class E is the least profitable, because fewer people are very regular (only 6.9%):
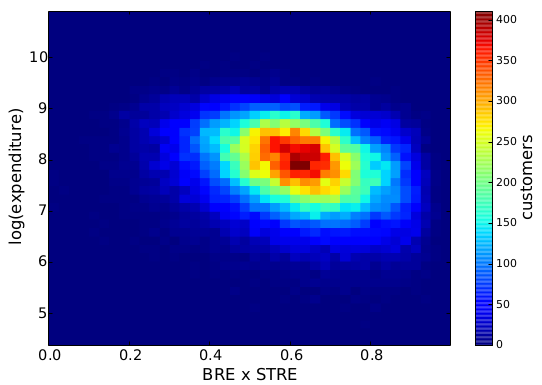
Without dividing customers in discrete classes, we can see what is the direct relationship between behavioral entropy and the yearly expenditure of a customer. This aggregated behavioral entropy measure is simply the multiplication of basket and spatio-temporal entropy. Unsurprisingly, entropy and expenditure are negatively correlated:
Finally, we want to quantify this relationship. We want to have an objective way to tell how much more money the supermarket could make if the customers would be more regular. We didn’t get too fancy here, just a linear model where we try to predict the customers’ expenditures from their basket and spatio-temporal entropy. We don’t care very much about causation here, we just want to make the point that basket and spatio-temporal entropy are interesting measures.

The negative sign isn’t a surprise: the more chaotic a customer’s life, the lower her expenditures. What the coefficients tell us is that we expect the least chaotic (0) customer to spend almost four times as much as the most chaotic (1) customer*. You can understand why this was an extremely pleasant finding for me. This week, I’m going to print out the paper and ask to see the supermarket manager. I’ll tell him: “Hey, if you stop moving stuff around and you encourage your customers to be more and more regular, maybe you could increase your revenues”. Only that I won’t do it, because that’d break my Saturday shopping routine. Oh dear.
* The interpretation of coefficients in regressions are a bit tricky, especially when transforming your variables with logs. Here, I just jump straight to the conclusion. See here for the full explanation, if you don’t believe me.
