Data: the More, the Merrier. Right? Of Course Not
You need to forgive me for the infamous click-bait title I gave to the post. You literally need to, because you have to save your hate for the actual topic of the post, which is Big Data. Or whatever you want to call the scenario in which scientists are flooded with so much data that traditional approaches break, for one reason or another. I like to use the Big Data label just because it saves time. One of the advantages of Big Data is that it’s useful. Once you can manage it, simple analysis will yield great profits. Take Google Translate: it does not need very sophisticated language models because millions of native speakers will contribute better translations, and simple Bayesian updates make it works nicely.

Of course there are pros and cons. I am personally very serious about the pros. I like Big Data. Exactly because of that love, honesty pushes me to find the limits and scrutinize the cons of Big Data. And that’s today’s topic: “yet another person telling you why Big Data is not such a great thing (even if it is, sometimes)” (another very good candidate for a click-bait title). The occasion for such a shameful post is the recent journal version of my work on human mobility borders (click for the blog post where I presented it). In that work we analysed the impact of geographic resolution on mobility data to locate the real borders of human mobility. In this updated version, we also throw temporal resolution in the mix. The new paper is “Spatial and Temporal Evaluation of Network-Based Analysis of Human Mobility“. So what does the prediction of human mobility have to do with my blabbering about Big Data?
Big Data is founded on the idea that more data will increase the quality of results. After all, why would you gather so much data at the point of not knowing how to manage them if it was not for the potential returns? However, sometimes adding data will actually decrease the research quality. Take again the Google Translate example: a non native speaker could add noise, providing incorrect translations. In this case the example does not really hold, because it’s likely that the vast majority of contributions comes from people who are native speakers in one of the two languages involved. But in my research question about human mobility it still holds. Remember what was the technique in the paper: we have geographical areas and we consider them nodes in a network. We connect nodes if people travel from an area to another.

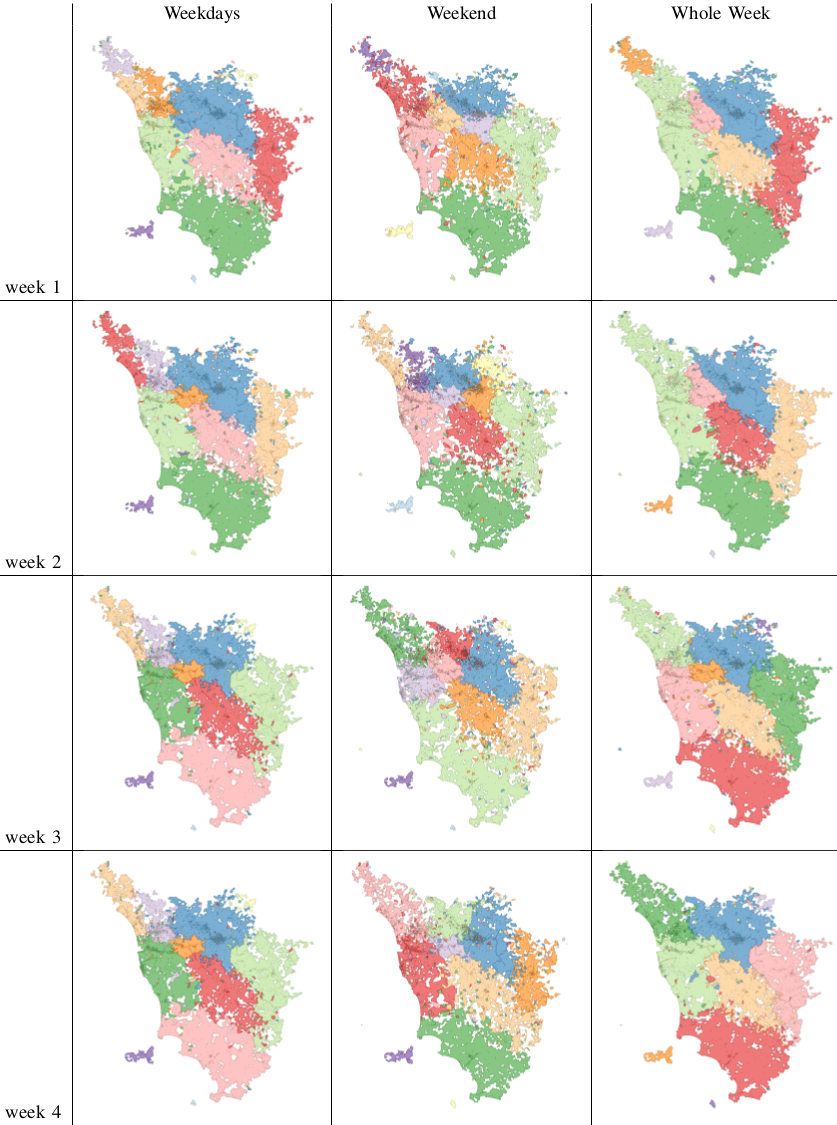
Let’s start from a trivial observation. Weekends are different from weekdays. There’s sun, there’s leisure time, there are all those activities you dream about when you are stuck behind your desk Monday to Friday. We expect to find large differences in the networks of weekdays and in the networks of weekends. Above you see three examples (click for larger resolution). The number of nodes and edges tells us how many areas are active and connected: there are much fewer of them during weekends. The number of connected components tells us how many “islands” there are, areas that have no flow of people between them. During weekends, there are twice as much. The average path length tells us how many connected areas you have to hop through on average to get from any area to any other area in the network: higher during weekdays. So far, no surprises.
If you recall, our objective was to define the real borders of the macro areas. In practice, this is done by grouping together highly connected nodes and say that they form a macro area. This grouping has the practical scope of helping us predict within which border an area will be classified: it’s likely that it won’t change much from a day to another. The theory is that during weekends, for all the reasons listed before (sun’n’stuff), there will be many more trips outside of a person’s normal routine. By definition, these trips are harder to predict, therefore we expect to see lower prediction scores when using weekend data.

The first part of our theory is proven right: there are indeed much less routine trips during weekends. Above we show the % of routine trips over all trips per day. The consequences for border prediction hold true too. If you use the whole week data for predicting the borders of the next week you get poorer prediction scores. Poorer than using weekday data for predicting weekday borders. Weekend borders are in fact much more volatile, as you see below (the closer the dots to the upper right corner, the better the prediction, click for higher resolution):

In fact we see that the borders are much crazier during weekends and this has a heavy influence on the whole week borders (see maps below, click for enjoying its andywarholesque larger resolution). Weekends have a larger effect on our data (2/7), much more than our example in Google Translate.
The conclusion is therefore a word of caution about Big Data. More is not necessarily better: you still need theoretical grounds when you add data, to be sure that you are not introducing noise. Piling on more data, in my human mobility study, actually hides results: the high predictability of weekday movements. It also hides the potential interest of more focused studies about the mobility during different types of weekends or festivities. For example, our data involves the month of May, and May 1st is a special holiday in Italy. To re-ignite my Google Translate example: correct translations in some linguistic scenarios are incorrect otherwise. Think about slang. A naive Big Data algorithm could be caught in between a slang war, with each faction claiming a different correct translation. A smarter, theory-driven, algorithm will realize that there are slangs, so it will reduce its data intake to solve the two tasks separately. Much better, isn’t it?
