Node Attribute Distances, Now Available on Multilayer Networks! (Until Supplies Last)
I’ve been a longtime fan of measuring distances between node attributes on networks: I’ve reviewed the methods to do it and even proposed new ones. One of the things bothering me was that no one had so far tried to extend these methods to multilayer networks — networks with more than one type of relationships. Well, it bothers me no more, because I just made the extension myself! It is the basis of my new paper: “Generalized Euclidean Measure to Estimate Distances on Multilayer Networks,” which has been published on the TKDD journal this month.

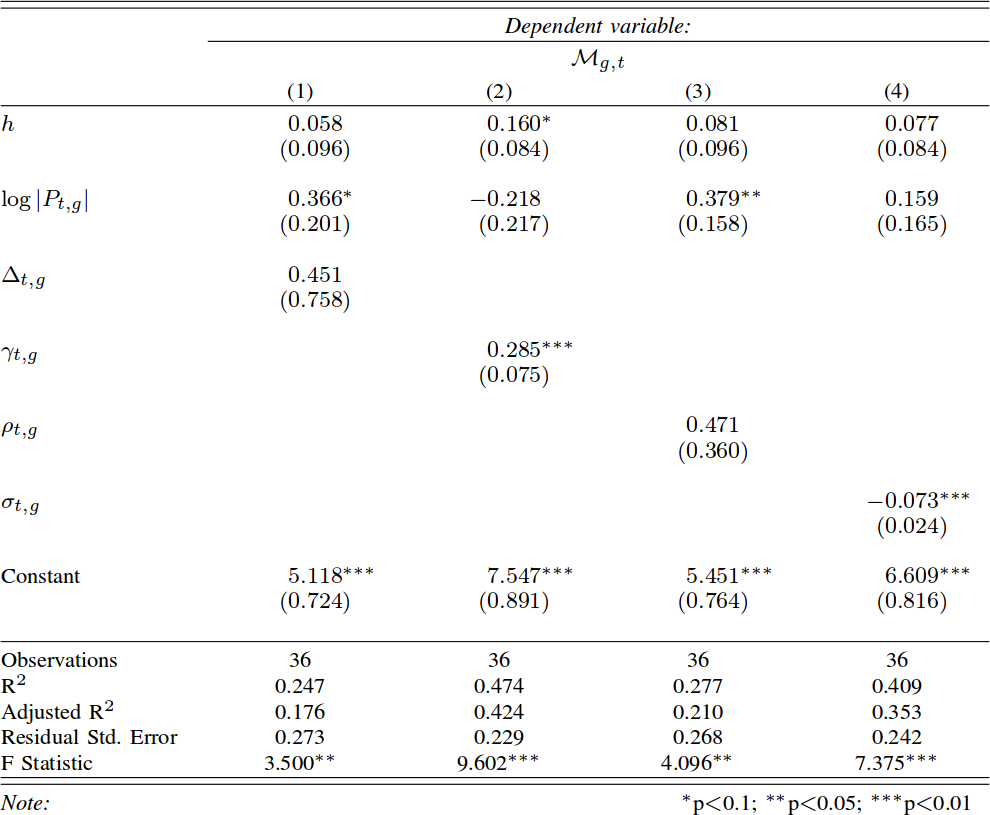
You might be wondering: what does it mean to “measure the distance between node attributes on networks”? Why is it useful? Let’s make a use case. The Product Space is a super handy network connecting products on the global trade network based on their similarity. You can have attributes saying how much of a product a country exported in a given year — in the image above you see what Egypt exported in 2018. This is super interesting, because the ability of a country to spread over all the products in the Product Space is a good predictor of their future growth. The question is: how can we tell how much the country moved in the last ten years? Can we say that country A moved more or less than country B? Yes, we can! Exactly by measuring the distance between the node attributes on the network!
The Product Space is but an example of many. One can estimate distances between node attributes when they tell you something about:
- When and how much people were affected by a disease in a social network;
- Which customers purchased how many products in a co-purchase network (à la Amazon);
- Which country an airport belongs to in a flight network;
- etc…

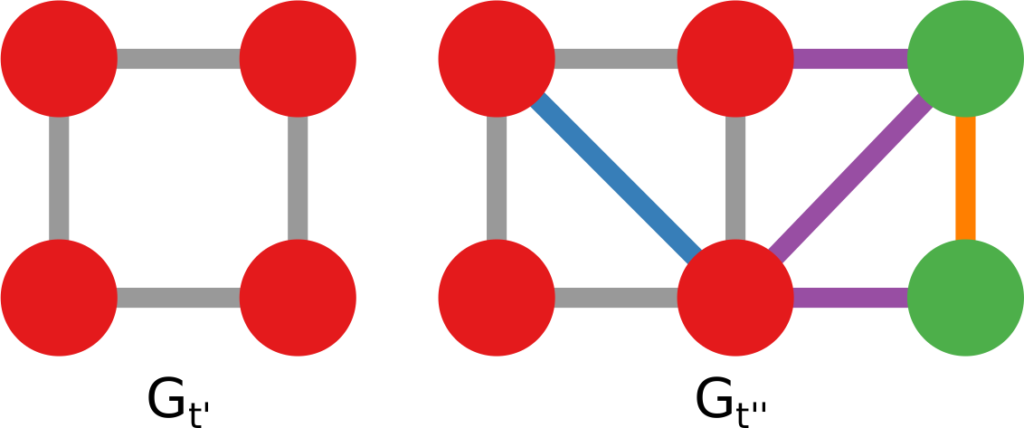
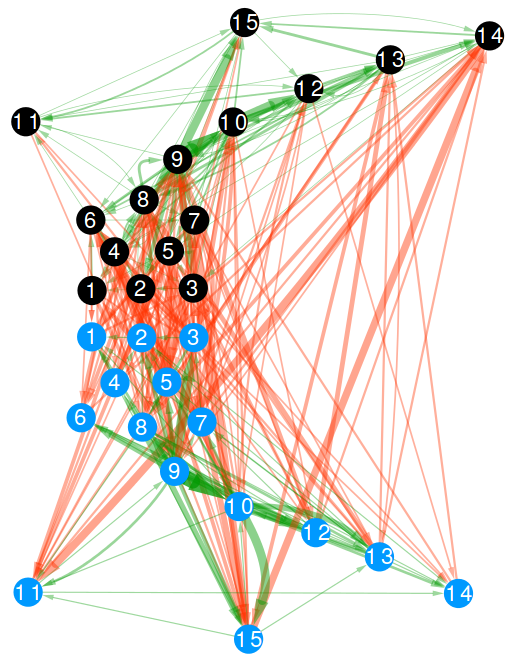
Let’s focus on that last example. In this scenario, each airport has an attribute per country: the attribute is equal to 1 if the airport is located in that country, and 0 otherwise. The network connects airports if there is at least a flight planned between them. In this way, you could calculate the network distance between two countries. But wait: it’s not a given that you can fly seamlessly between two countries even if they are connected by flights across airports. You could get from airport A to airport B using flight company X, but it’s not a given than X provides also a flight to airport C, which might be your desired final destination. You might need to switch to airline Y — the image above shows the routes of four different companies: they can be quite different! Switching between airlines might be far from trivial — as every annoyed traveler will confirm to you –, and it is essentially invisible to the measure.
It becomes visible if, instead of using the simple network I just described, you use a multilayer network. In a multilayer network, you can say that each airline is a layer of the network. The layer only contains the flight routes provided by that company. In this scenario, to go from airport A to airport C, you pay the additional cost of switching between layers X and Y. This cost can be embedded in my Generalized Euclidean measure, and I show how in the paper — I’ll spare you the linear algebra lingo.

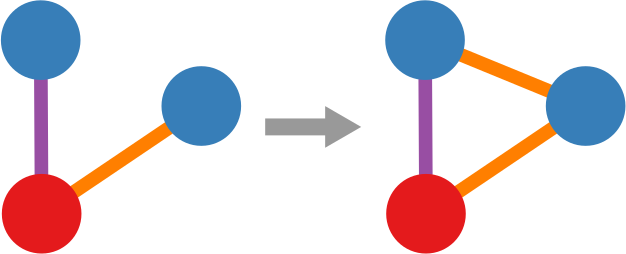
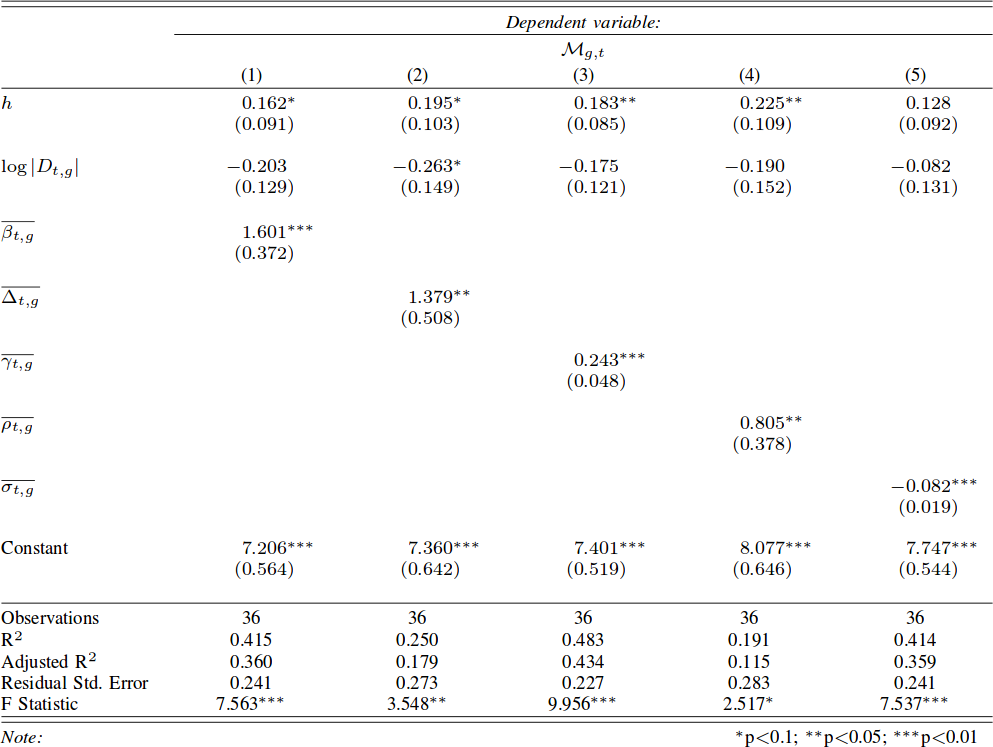
One thing I’ll say — though — is that there are easy ways to embed such layer-switching costs in other measures, such as the Earth’s Mover Distance. However, these measures all consider edge weights as costs — e.g., how long does it take to fly from A to B. My measure, instead, sees edge weights as capacities — e.g. how many flights the airline has between A and B. This is not splitting hairs, it has practical repercussions: edge weights as costs are ambiguous in linear algebra, because they can be confused with the zeros in the adjacency matrices. The zeros encode absent edges, which are effectively infinite costs. Thus there is an ambiguity* in measures using this approach: as edges get cheaper and cheaper they look more and more like infinitely costly. No such ambiguity exists in my approach. The image above shows you how to translate between weights-as-costs and weights-as-capacities, and you can see how you can get in trouble in one direction but not in the other.
In the paper, I show one useful case study for this multilayer node distance measure. For instance, I am able to quantify how important the national flagship airline company is for the connectivity of its country. It’s usually extremely important for small countries like Belgium, Czechia, or Ireland, and less crucial for large ones like France, the UK, or Italy.
The code I developed to estimate node attribute distances on multilayer networks is freely available as a Python library — along with data and code necessary to replicate the results. So you have no more excuses now: go and calculate distances on your super complex super interesting networks!
* This is not completely unsolvable. I show in the paper how one could get around this. But I’d argue it’s still better not to have this problem at all 🙂










{kind=link}