I am an associate prof at IT University of Copenhagen. I mainly work on algorithms for the analysis of complex networks, and on applying the extracted knowledge to a variety of problems.
My background is in Digital Humanities, i.e. the connection between the unstructured knowledge and the coldness of computer science.
I have a PhD in Computer Science, obtained in June 2012 at the University of Pisa. In the past, I visited Barabasi's CCNR at Northeastern University, and worked for 6 years at CID, Harvard University.
I am an associate prof at IT University of Copenhagen. I mainly work on algorithms for the analysis of complex networks, and on applying the extracted knowledge to a variety of problems.
My background is in Digital Humanities, i.e. the connection between the unstructured knowledge and the coldness of computer science.
I have a PhD in Computer Science, obtained in June 2012 at the University of Pisa. In the past, I visited Barabasi's CCNR at Northeastern University, and worked for 6 years at CID, Harvard University. The Paradox of Social Controllability
“It’s a bit sad that some among the most brilliant minds of our generation are working tirelessly on strategies to increase clicks on online ads” popped up on my Facebook stream some days ago (I don’t remember who wrote it, so you are welcome to contact me to restore credit where credit is due 🙂 ). But the point still remains. I actually don’t find it that bad. Yes, it’s bad, but it could be worse. It reminds me of other “wrong” reasons to do incredible improvements in science and stuff. For example, war is responsible for many technology advancements. Even if the aim of online marketing is just to increase revenues, what it actually requires is to understand human psychology, behavior and social interactions. In practice, that’s philosophy of the human mind at its best: how does the brain work? How does a collection of brains work? What drives our behavior and needs?
When you put together many minds in the real world, you have to deal with complex networks. We are not connected with one another at random, and the eyes of our friends are the channel through which we observe the world. This fact is studied in complex network analysis, in the sub-branch of cascade behaviors. Cascade behaviors happen when a person in a social network decides to modify her behavior according to the behavior of the people she is connected to. As a consequence, there are some people in the network who are in a very particular position: given the people they know and their prominence among them, they can modify their behavior and they will modify their friends’ behavior and so on an so forth, changing forever how every node in the network behaves. And that’s the cascade. If you find a way to identify these prominent actors in the network, you can control the behavior of the entire system. Now you can see why there is a mountain of work about it. In the computer science approach, we have threshold models simulating the cascade for many starting nodes and thus identify the practical leaders (for example Jon Kleinberg’s work); in physics we have models, aiming at understanding the degree of controllability of complex systems (I’ll go with Laszlo Barabasi in this).

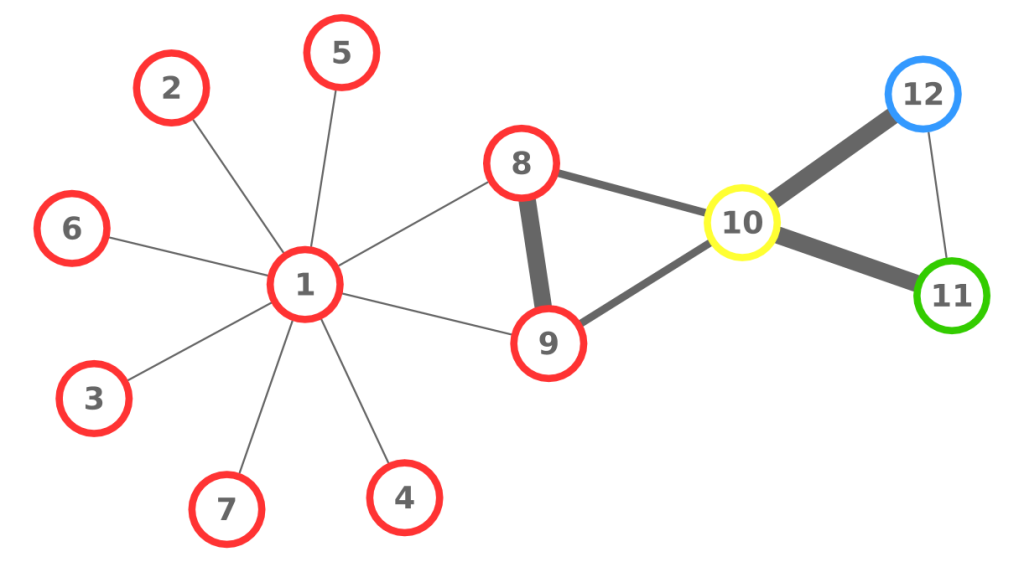
Visualization of network cascade, from my good friend Mauro Martino. The red dots at the bottom are the “drivers”, who influence the collection of green nodes they are attached to.
Genuinely curious about the topic, I started my own track of research on it. One thing that Diego Pennacchioli, Giulio Rossetti, Luca Pappalardo, Dino Pedreschi, Fosca Giannotti and me found curious is that everybody working on social prominence was looking at it from a monodimensional perspective. That means: the only thing they are interested in is how to maximize the number of nodes influenced by the leaders. The bigger this number, the better. All fun and games, but why? I can think about several scenarios where the final total number is not the most important thing. For example:
- What if I want people to buy a product? The total number of people knowing about the product is nice, but I want them to be strongly committed, strongly enough to buy it.
- What if I am actually looking to reach a particular person? Then I care how deeply my message can go through the network.
- What if I just care about my friends? Then screw their friends (and everybody else), as long as I can influence a wide range of my direct connections!
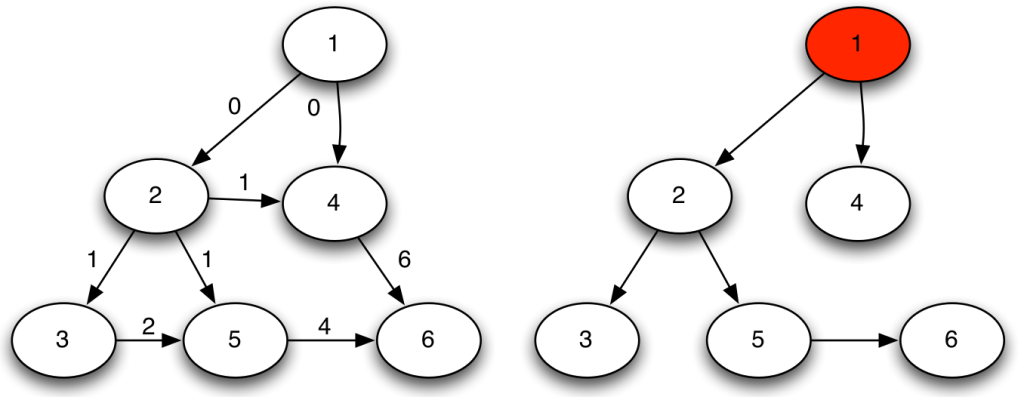
To calculate our measure we need to infer the diffusion trees. So from the left, where the number on each arrow gives you the action time of the node at the base of the arrow, we go to the right by selecting the lowest possible combination of arrows.
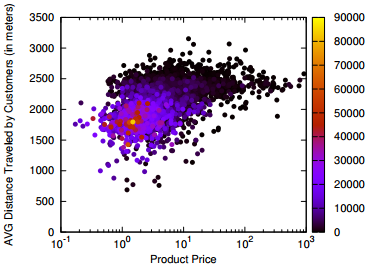
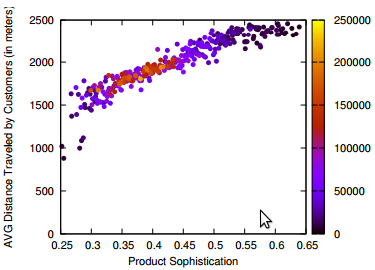
Strength, depth and width of social prominence. That’s why our paper is called “The Three Dimensions of Social Prominence” (check it out). Strength is how committed the people you influenced are to keep doing what you influenced them to do. Depth is how many degrees of separation (or, how far) the cascade of influence that you triggered can go. Width is simply the ratio of your friends that you are able to influence. By analyzing how much a user in Last.fm (a social website based on music) is able to influence her friends in listening to new artists, we found a collection of very interesting facts.
For example, it is well known that in social networks there are some nodes that are structurally very important. They are the central users, the ones that keep the network connected. Intuitively, they are the only way, or the easiest way, through which a signal (in our case social influence) can go from one part of the network to the other. Guess what: they can’t do it. We found a significant anti-correlation between centrality and width and depth. That is bad news, because those nodes are the ones in the only position with a theoretical ability of controlling the network and a practical inability in doing so. I like to call it “The Paradox of Social Controllability” (hence, the post title).
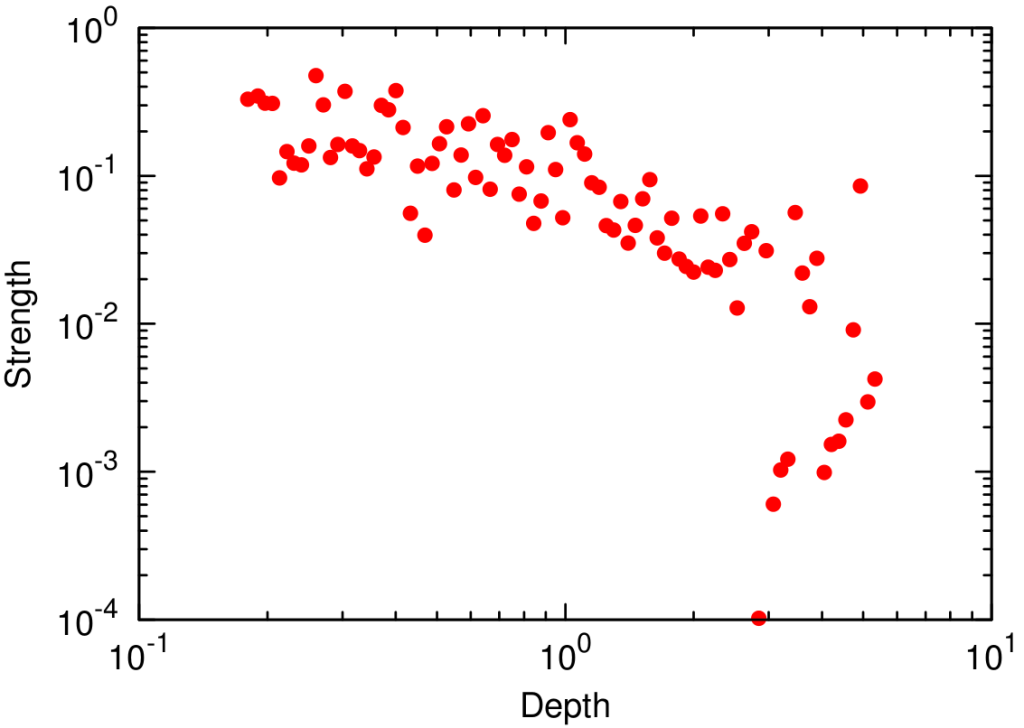
The anti-correlation between depth and strength.
Another piece of food for thought is the trade off between strength and depth. While width is unrelated to both, we found that if you want to go deeply into the network, then you can’t expect that the people you touch will be extremely committed to your message.
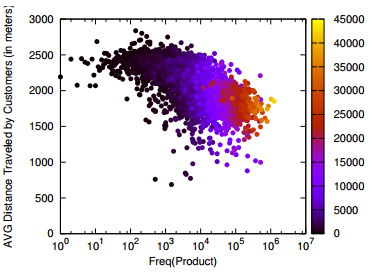
The third big thing is the distribution of connections per leader. We found that the leaders showing highest values of strength, depth and width were those who used Last.fm with average frequency. The highly connected and very active users (hubs, in network lingo) scored poorly, as we saw. So did the occasional users, the ones with just two or three connections (that is the majority of the system). The people who have control over the network are the mildly engaged. They are you, in practice: chances are that you are not a record label, nor a music fanatic, but just a person with her tastes and preferences. So you have control. Problem is, the control is scattered equally on the vast set of people like you.
To conclude, we saw what wonderful things network cascades are: they could empower us to do a lot of good. We also saw how there are theoretical results about the possibility of identifying people who can trigger them. But my unfortunate conclusion is about the paradox between theory and practice. Those who theoretically should, apparently can’t.